
Machine Learning- und AI-Technologien erleben derzeit einen enormen Boom. Computer können inzwischen Autofahren, Hunderassen besser auseinanderhalten als Experten und besiegen menschliche Spieler sowohl in traditionellen Spielen wie Schach oder Go, als auch in komplexen aktuellen Computerspielen. Fast täglich gibt es auf immer mehr Gebieten Pressemeldungen über die neuesten Errungenschaften der „künstlichen Intelligenz“. Doch Vieles, was als vermeintliches AI-System verkauft und angepriesen wird, hat mehr mit einem von Menschen generierten Entscheidungsbaum gemein, als mit echter Intelligenz. Denn von dieser ist der aktuelle Stand der Forschung noch weit entfernt.
Für eine sinnvolle Diskussion der Einsatzmöglichkeiten einer AI im Steuerbereich möchten wir zunächst einige Definitionen voranstellen, beginnend mit der Differenzierung des Begriffs AI selbst. Künstliche Intelligenz, AI, ist ein sehr breiter Begriff und umfasst sowohl die schon heute technologisch verfügbare „weak“ AI (wAI), als auch die künstliche Superintelligenz der Zukunft, die im Allgemeinen als Artificial General Intelligence (AGI) bezeichnet wird. Eine wAI weist typischerweise eine hohe Spezialisierung auf und ihre Intelligenz ist auf bestimmte, vordefinierte Aufgabengebiete beschränkt. Auch wenn Chatbots wie Cortana und Siri, selbstfahrende Autos, Gesichtserkennung und die eingangs aufgezählten Anwendungen oftmals mit „intelligenten“ Ergebnissen beeindrucken, so fallen sie dennoch unter den Begriff der wAI. Eine AGI könnte hingegen Gelerntes beliebig auf andere Aufgabengebiete abstrahieren und hätte die Fähigkeit zum richtigen „Denken“. Dies ist derzeit noch (weit entfernte) Zukunftsmusik, müsste z.B. durch ein überzeugendes Bestehen des Turing-Tests verifiziert werden und hätte z.B. auch philosophisch und ethisch weitreichende Implikationen.
Die meisten der jüngsten Fortschritte wurden mithilfe von Deep Learning erzielt. Deep Learning ist ein Machine Learning-Algorithmus und basiert auf sogenannten Neuronalen Netzen (NN), welche das Zusammenspiel von Neuronen im menschlichen Gehirn imitieren. Große Teile der Funktionsweise des Gehirns sind allerdings nach wie vor unbekannt bzw. (noch) nicht imitierbar, weshalb die Entwicklung einer echten AGI bisher nicht absehbar ist. Neuronale Netze sind besonders gut in der Mustererkennung und der Kategorisierung von Daten, weshalb die aktuelle „AI-Revolution“ auch mit der Kategorisierung von Bildern begann. Ein gut trainiertes Netz kann mit hoher Präzision Muster auf verschiedenen Ebenen erkennen und diese im Anschluss bereits gelernten Kategorien zuordnen. Diese gelernten Kategorien können dabei entweder a-priori vorgegeben sein (Supervised Learning) oder vom Lern-Algorithmus aus den Daten selbst ohne weiteren Input von außen generiert werden (Unsupervised Learning).
Dieser Beitrag beschäftigt sich mit aktuell möglichen Einsatzgebieten moderner AI-Technologie im Steuerbereich. Daher werden insbesondere die Einsatzmöglichkeiten der heute schon realisierbaren wAI auf Basis Neuronaler Netze thematisiert.
Beispielhafte Anwendungsfälle und Voraussetzungen für einen erfolgreichen Einsatz von AI-Technologien im Steuerbereich
Die Anwendungsmöglichkeiten für wAI/Machine Learning-Technologien im Steuerbereich sind vielfältig. Dazu gehören z.B. die automatisierte Auswertung von unstrukturierten Text-Daten aus Verträgen oder die Erkennung und Vorsortierung problematischer Buchungsvorgänge während einer Kontrolle.
Auch die Kategorisierung von Buchungsvorgängen zu den jeweils passenden Steuerschlüsseln wäre ein möglicher Einsatzbereich, den wir im Folgenden beispielhaft darstellen möchten. Ein großer Vorteil einer auf neuronalen Netzen basierenden wAI gegenüber einfacheren, regelbasierten Verfahren ist, dass keine direkte Kommunikation zwischen dem menschlichen Bearbeiter und der Maschine bestehen muss und keine langwierige und oftmals fehlerbehaftete manuelle Übertragung bzw. Encodierung des jeweiligen Expertenwissens notwendig ist. Gleichzeitig können auch komplexe, nicht-lineare Zusammenhänge gelernt werden, ohne dass entsprechende Features vorher aufwendig manuell aufbereitet werden müssen. Die wAI entwickelt selbstständig auf Basis des Datenbestandes und der Zielvorgaben ein Zuordnungssystem. In unserem Beispiel könnte ein Datenbestand aus bereits zu Steuerschlüsselkategorien zugeordneter Vorgänge der vergangenen Monate verwendet werden, welche die wAI dann zum Lernen nutzt (siehe Abbildung 1 für eine schematische Darstellung).
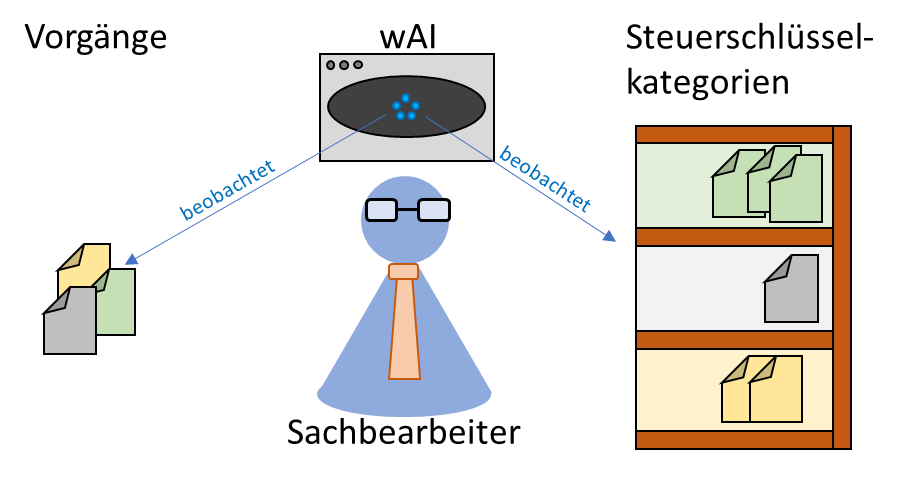
Während des Lernens muss mittels Parameterwahl und in Abhängigkeit von der Datenverfügbarkeit ein möglichst optimaler Kompromiss zwischen Underfitting (Generalisierbarkeit/Bias) und Overfitting (Genauigkeit/Variance) gefunden werden. Doch auch bei einer optimalen Parametrisierung kann es im praktischen Einsatz zu Problemen kommen. So können neue Vorgänge, die zu keiner bisher gelernten Steuerschlüssel-Kategorie passen, durch die fehlende Möglichkeit der Akkommodation der wAI nicht automatisch einer neu geschaffenen Kategorie zugeordnet werden (Abbildung; 2 links). Wenn sich der neue Vorgang signifikant von den bisher bekannten Vorgängen unterscheidet, würde er durch Schwierigkeiten bei der Zuordnung (d.h. eine niedrige prognostizierte Wahrscheinlichkeit für alle bisher bestehenden Kategorien) auffallen und an den Sachbearbeiter gemeldet werden. Neue Vorgänge, die bereits existierenden Kategorien stark ähneln, können hingegen zu Fehlklassifikationen führen (siehe Abbildung 2; rechts).
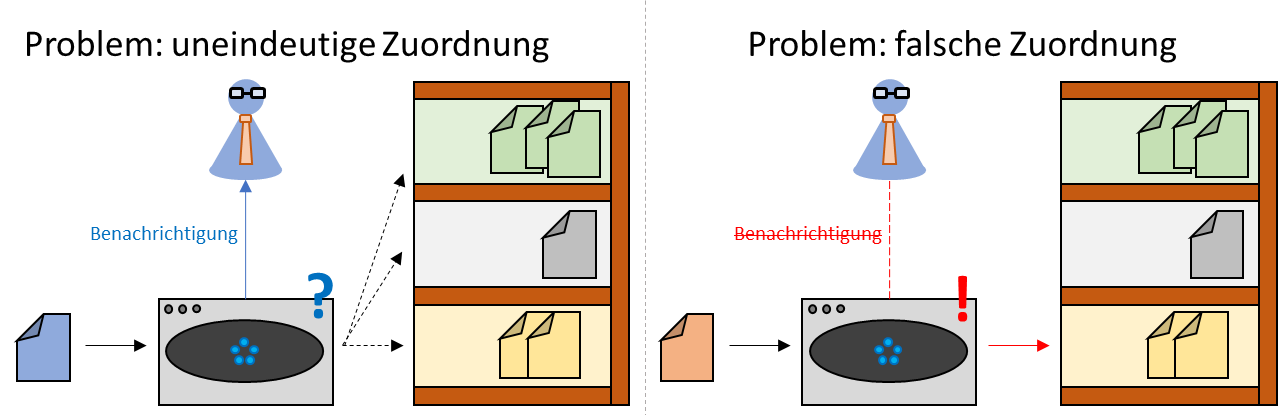
Diese potentiellen Probleme können am besten durch eine verbesserte Datengrundlage gemindert werden. Allgemein gilt, dass die Performance von Deep Learning Algorithmen in der Regel steigt, wenn mehr Trainingsdaten verwendet werden. Vielfach kann ein simpler Algorithmus mit vielen Daten eine stärkere Performance erreichen, als ein komplexer Algorithmus mit wenigen Daten. Trainingsdatensätze mit Tausenden oder besser Hunderttausenden von bereits richtig klassifizierten Beispielen sind daher unerlässlich. Ähnelt die Aufgabenstellung der wAI stark der einer anderen, bereits angelernten wAI, dann kann die Erfahrung oftmals mittels “Transfer Learning” übertragen werden. So wäre es möglich, auch für vergleichsweise wenige Beobachtungen gute Ergebnisse zu liefern oder die wAI mit wenig Umstellungsaufwand in einem anderen, ähnlichen Aufgabengebiet einzusetzen.
Für unser Beispiel der Steuerschlüssel-Kategorisierung ergibt sich folgende Konsequenz: Die Performance der wAI – gemessen in der Richtigkeit der Kategorisierung – ist stark abhängig vom vorhandenen Datenbestand. Im Falle einer umfassenden Datenbasis von korrekt gelabelten Vorgängen für den Lernprozess sollte die Performance der wAI (zumindest für Standard-Vorgänge) schnell die Performance des Sachbearbeiters übertreffen, so dass sich dieser nur noch um neue bzw. Sonderfälle kümmern müsste.
Zusammenfassend lässt sich sagen, dass insbesondere die folgenden 3 Voraussetzungen, den Einsatz einer wAI im Beispiel, aber auch allgemein begünstigen:
- Klar definierte, möglichst statische Problemstellung mit eindeutigem Ziel (im Beispiel: Zuordnung von passenden Steuerschlüsseln zu Vorgängen).
- Das Problem muss bereits bekannt bzw. gelöst sein und es muss eine eindeutige richtige Antwort geben (im Beispiel: Zuordnung der Steuerschlüssel durch den Sachbearbeiter).
- Es müssen genügend Trainings-Datensätze vorliegen, um den wAI-Algorithmus trainieren zu können (im Beispiel: bereits manuell zugeordnete Steuerschlüssel aus der Vergangenheit).
Aktuelle Situation und Zusammenfassung
Werden die oben genannten Voraussetzungen erfüllt, kann der Einsatz einer wAI zu Kostenersparnissen, der Beschleunigung von Prozessen und einer Risikominderung führen. In unserem Beispiel könnte eine gut trainierte wAI innerhalb kürzester Zeit tausende von Vorgängen präzise kategorisieren. Ist sich die wAI bei der Zuordnung eines Vorgangs zu einem Steuerschlüssel nicht sicher, übernimmt der Sachbearbeiter die Kategorisierung.
In der Praxis werden immer mehr unternehmensweite ERP-Systeme eingesetzt. Dies führt zu steigender Datenhomogenität und einem steigenden Grad der Automatisierung. Außerdem liegen immer mehr Informationen in maschinenlesbarer Form vor und können direkt aus bestehenden Systemen geladen werden. Dies sind auf den ersten Blick optimale Voraussetzungen für die Implementierung und Nutzung einer wAI. Das Steuerrecht unterliegt in seiner Natur jedoch häufigen Veränderungen. Gerade strukturelle Änderungen in Gesetzen führen dazu, dass nicht alle steuerlichen Sachverhalte immer zeitnah in einer integrierten ERP-Lösung dargestellt werden können und die vorhandenen Daten somit oftmals nicht genutzt werden können bzw. bereits angelernte wAI-Modelle nicht problemlos weiter verwendet werden können.
Zusammenfassend lässt sich sagen, dass (w)AI- und ML-Technologien auch im Steuerbereich zunehmend an Bedeutung gewinnen und schon heute in vielen Bereichen unterstützend zum Einsatz kommen. Während komplexe Beratungsprojekte mittelfristig weiterhin „manuell“ durchgeführt werden müssen, lassen sich schon heute insbesondere Prozesse mit einem hohen Volumen an ähnlichen Vorgängen und einer guten Datenbasis mit vertretbarem Zeit- und Kostenaufwand weitgehend automatisieren. Diese Möglichkeiten sollten von Unternehmen auch schon vorbereitet werden (z.B. durch standardisierte Datenerhebung), wenn die Technologien selbst (noch) nicht genutzt werden.
Max Udo Giacomo Niederwettberg
Steuerberatungsassistent, bei Flick Gocke Schaumburg
Jan Philipp Harries
Co-Founder, QuantAI GmbH
